Lead Generation from ProxyCurl into Sheet Best with Python

Sales are the lifeblood of all businesses. A company will not survive without sales. Applying technology to your lead generation system can be one of the best investments for a company. With the focus to maintain & cultivate an existing business relationship while forming new relationships with new customers.
Therefore for this article, we will be using Proxycurl to gather LinkedIn data for potential leads for your company. Armed with these new leads, we will use Sheet Best to save all of these data into Google Sheet in a fuss-free manner.
System Architecture

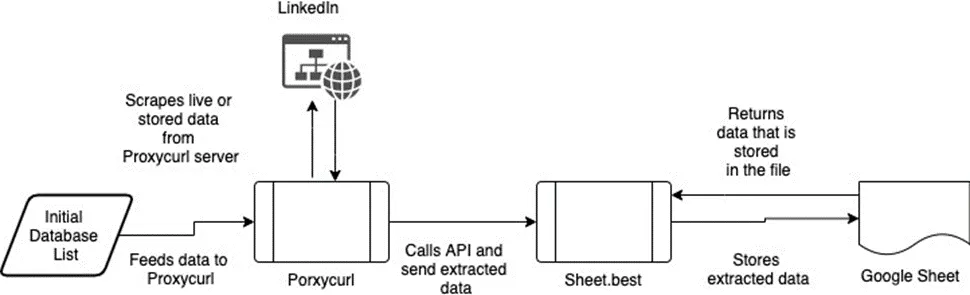
System Architecture of the Solution
Here’s the breakdown of how the system architecture will work:
-
Proxycurl - Will be gathering data from Linkedin on their API service.
-
Sheet Best - The API service that acts as the middleman. Who saves the data you had gathered from ProxyCurl into a Google sheet.
-
Google Sheets - The place where you will be storing your Proxycurl data for further processing into prospects for your company.
Requirements
Here are the requirements to get started with the project
-
Google Sheets - A Google sheet with a public link so that you can edit the google sheet
-
Sheet Best - A account to integrate by passing data from Proxycurl through your python program to Google sheet.
-
Visual Studio Code - Your text editor for the project
-
Github - To clone the git repo to get the source code from GitHub
-
Python libraries installed with:
Project Structure
You can get the source code from the Github repo from this link [https://github.com/sheetbest/ProxycurlXSheet Best](https://github.com/sheetbest/ProxycurlXSheet Best)
|— README.md - Details on how to set up and run the various programs in the repo
|— final.py - The integration of both Proxycurl and Sheet Best to save the data into a Google Sheet
|— proxycurl_quickstart.py - Proxycurl quickstart program
|— requirements.txt - Your python packages needed for this article
|— sheet_best_quickstart.py - Sheet Best quickstart program
|— venv - The name of your virtual environment
|— .env - Contains the API keys for Proxycurl and Sheet Best API URL
Gathering Leads with ProxyCurl

I won’t suggest you by building your own Linkedin scrapper from scratch. It is both a frustrating & time-consuming process due to the number of preventive measures by Linkedin.
Especially most data scrapping alternative requires your Linkedin profile account. Therefore this increases your chances of being blocked by Linkedin if you do not know what you are doing.
So that is why ProxyCurl does the hard work for you and provides tons of REST APIs that allows you to gather data from Linkedin. For this article, we will be using LinkedIn Person Profile Endpoint. We use this API is that consumes only one credit with just your trial account.
Setup
- Create a Proxycurl account https://nubela.co/proxycurl/auth/register
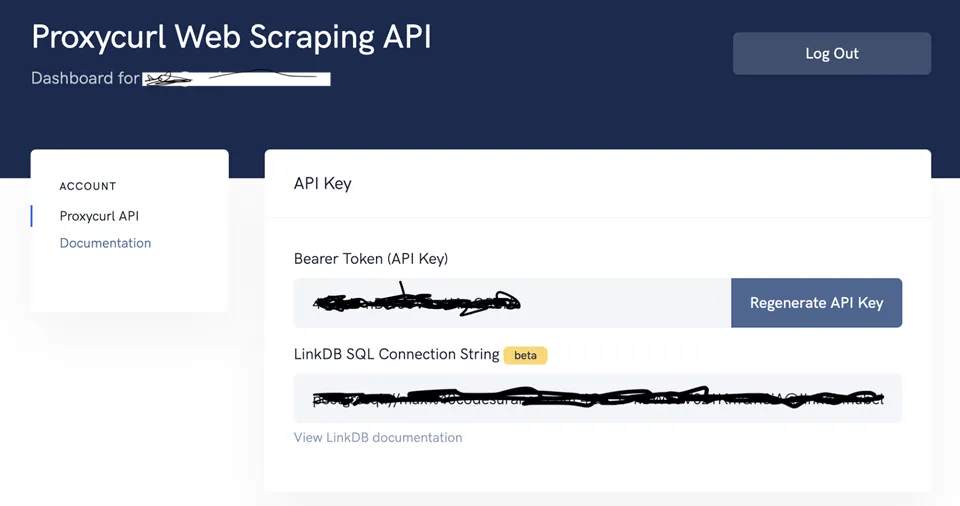
- Copy the Bearer Token (API Key)
- Now install these two Python libraries within your virtual environment
pip install requests python-dotenvAdd a .env in your root of the project called PROXYCURL with your ProxyCurl API key.

Quickstart with ProxyCurl
The first thing you do is to create a blank python file called “proxycurl_quickstart.py”. You can refer to the same file from the Github repo.
Now we shall import the various python libraries so that we can use the Proxycurl endpoint, declare our variables and pull the environment variables from the .env file:
proxycurl_quickstart.py
# importing of python libraries
import os
import requests
from dotenv import load_dotenv
load_dotenv() # Loads the .env configuration as part of your environment variables
proxycurl_api_key = os.getenv('PROXYCURL') # The API key from Proxycurl
# Proxycurl API endpoint called "LinkedIn Person Profile".
# For more details of the API - https://nubela.co/proxycurl/docs#people-api-linkedin-person-profile-endpoint
api_endpoint = 'https://nubela.co/proxycurl/api/v2/linkedin'
profile_url = 'your_linkedin_profile_url' # The LinkedIn profile url you want to get more information with_Now let’s add in both headers and parameters for the Proxycurl API call, and save the response into a response variable:
# The header & parameter configuration of the API
headers = {'Authorization': 'Bearer ' + proxycurl_api_key}
params = {'url': profile_url, 'use_cache': 'if-present'}
# The calling the API using request and save it into response
response = requests.get(api_endpoint, params=params, headers=headers)Now we are left with saving the result of the data by converting the response variable as JSON data type and saving it into data variable:
data = response.json() # Saves the API response as JSON into "data" variable
print_(data)Congrats if you endured and done well. Now execute the program the output will look like this:
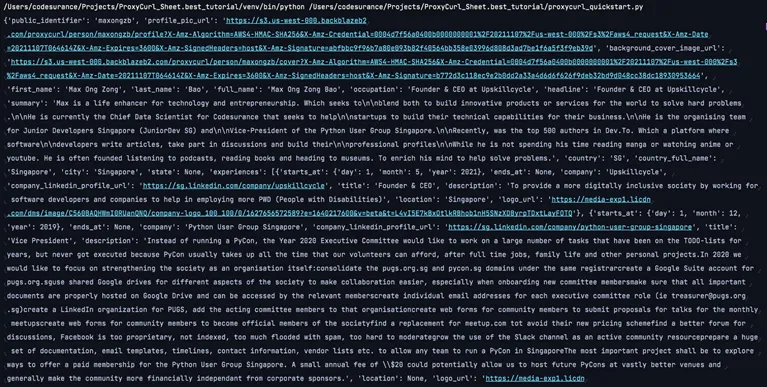
Storing Leads With Sheet Best

Photo by Jan Antonin Kolar on Unsplash
The purpose of Sheet Best is to act as a middle man. Sheet Best helps to bridge your python program with your files to store your data. This integration of your storage of choice can be either a Google sheet, Google drive folder or types of files like .csv & .xlsx files.
For this article, we will just be focusing on using a Google Sheet.
Setup
- Signup and create an account with Sheet Best using your Google account
- Create a new Google Sheet file in your google drive
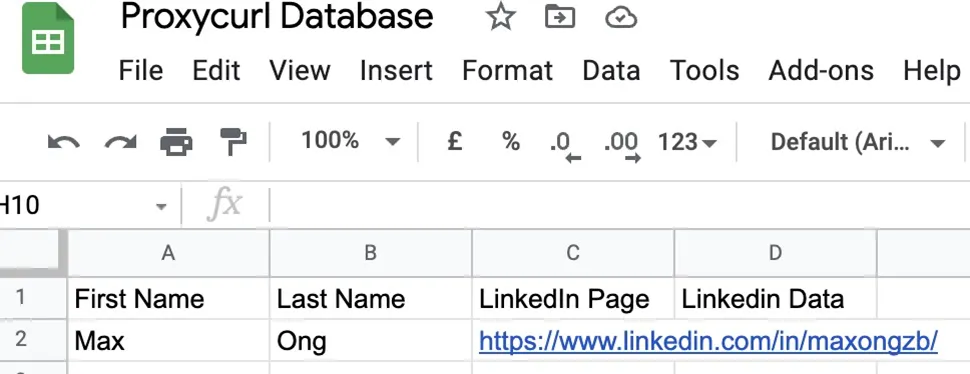
- Rename your Google Sheet to “Proxycurl Database”
- Add the “First Name”, “Last Name” and “LinkedIn Page” in the first row
- Add the following mock data in the 2nd row shown in the picture below.
- First Name - Max
- Last Name - Ong
- LinkedIn Page - https://www.linkedin.com/in/maxongzb/
- Linkedin Data - empty
- Share your google sheet as a public link with the editor permission for the file
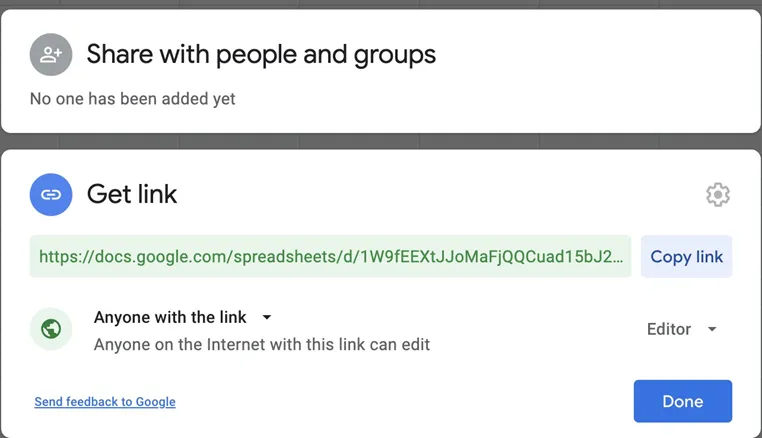
- Copy Google Sheet Public Link so that you will be using it later for Sheet Best
- Login to your Sheet Best account
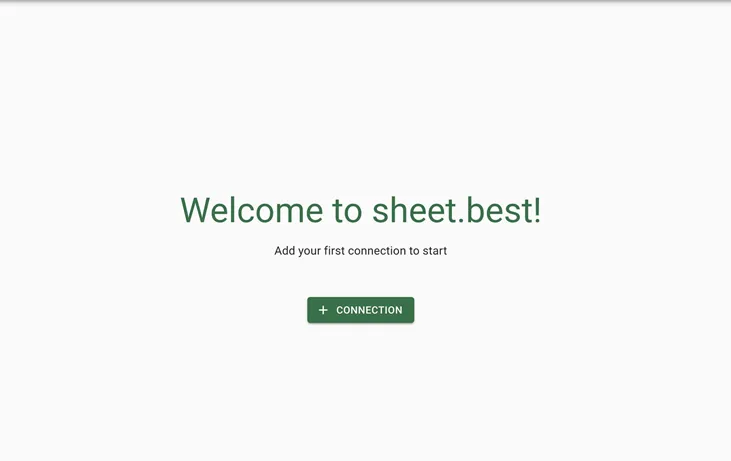
- Click on the “Add Connection” button to add a new connection with Sheet Best

-
Enter the following connection name, select “Google Sheet”, paste your google sheet link into the following:
-
Connection Name - Proxycurl Database
-
Connection (origin) - Google Sheet
-
Connection URL - Your Public Link with Editor Permission for your Google sheet.
-
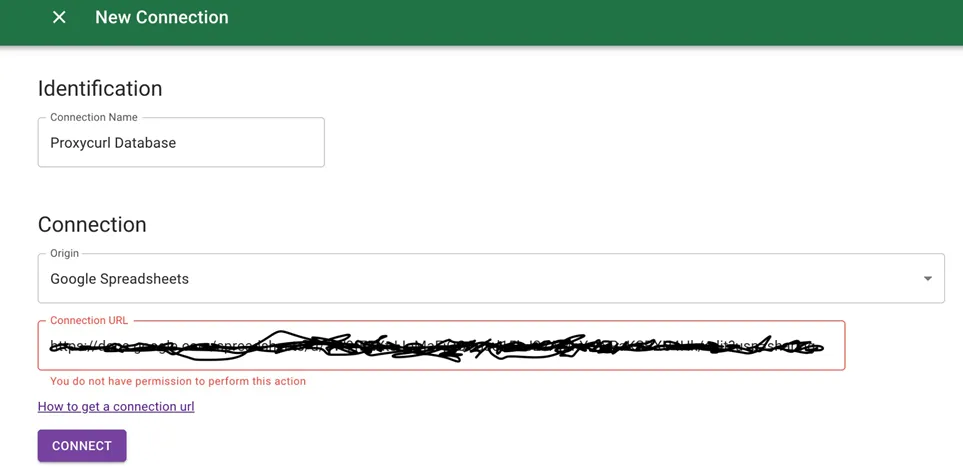
- Click on the “Connect” button to save the settings
Quickstart with Sheet Best
The first thing we will be doing is to import the python libraries and load the environment variables:
sheet_best_quickstart.py
# importing of python libraries
import_ os
import_ requests
from dotenv import load_dotenv
load_dotenv() # Loads the .env configuration as part of your environment variables_
sheet_best_connection_URL = os.getenv('SHEET_BEST_URL') # The API key from Proxycurl_Now we will be calling the API and saving it as the response variable. We will then convert the response variable data into a data variable and finally display it.
response = requests.get(sheet_best_connection_URL) # Saves the API response as JSON into "data" variable_
data = response.json()
print(data)Now you shall do the honours of executing the program which will display this.

Execute Success with the API Call
Integrating ProxyCurl Data Into Google Sheet with Sheet Best API
Now that you have a basic understanding of the Proxycurl and Sheet Best, we shall create three functions as follows under the file name called final.py:
get_linkedin_url- Requires a LinkedIn profile URL as a parameter. Pulls the LinkedIn data from the LinkedIn Person Profile Endpoint endpoint and returns the data as a JSON data type.save_linkedin_data- Requires the Linkedin data and position of the Google sheet that you want to update. This function will initiate a PUT request to save the LinkedIn data into the Google Sheet by using the Sheet Best connection url.display_google_sheet_data- Retrieves the data from Google Sheet using the Sheet Best connection url and displays it in the console.
The first thing we do is import all the various python libraries and declare the global variables:
final.py
# Importing the python libraries
import os
import requests
from dotenv import load_dotenv
# Declaring the global variables and pulling configuration settings from .env file
load_dotenv()
proxycurl_api_key = os.getenv('PROXYCURL')
sheet_best_api_url = os.getenv('SHEET_BEST_URL')
api_endpoint = 'https://nubela.co/proxycurl/api/v2/linkedin'
profile_url = 'your_linkedin_profile_url'Now, let us create the first function called get_linkedin_profile_data that gets data from the Proxycurl endpoint called “LinkedIn Person Profile Endpoint”:
def get_linkedin_profile_data(url):
# API headers & parameter declaration for the Proxycurl API endpoint
header_dic = {'Authorization': 'Bearer ' + proxycurl_api_key}
params = {
'url': url,
'use_cache': 'if-present',
}
try:
response = requests.get(api_endpoint, params=params, headers=header_dic)
# Try Catch block that captures the API response.
# If response returns a 200, this is considered successful
# if response code is not 200, this will be considered unsuccessful
if response.status_code == 200:
data = response.json()
print('======================Retrieve Data from Linkedin is Successful===================')
return data
else:
print('======================Retrieve Data from Linkedin is Unsuccessful==================')
return {'first_name': '', 'last_name': ''}
except Exception as err:
print({'Error: ': err.args})Now that we have the LinkedIn data, we will pass the data and save it into an existing row based upon the position of the row. Starting from 0 as the first row in the Google Sheet:
def save_linkedin_data(linkedin_data, position):
try:
# Updates the Google Sheet row based upon the "position" variable with the various linkedin_data for_
# updating the first name, last name & Linkedin data column in the Google sheet # For more information on how Google Sheet was updated you can visit this link # https://docs.Sheet Best/#put-patch-update-rows
response = requests.patch(f'{sheet_best_api_url}/{position}',
json={
'First Name': linkedin_data['first_name'],
'Last Name': linkedin_data['last_name'],
'LinkedIn Page': 'http://www.linkedin.com/in/maxongzb/',
'Linkedin Data': linkedin_data}
)
if response.status_code == 200:
print('=================Saving data to Google Sheet is Successful====================')
else:
print('=================Saving data to Google Sheet is Unsuccessful==================')
except Exception as err:
print({'Error: ': err.args})Now let’s retrieve all the data in the google sheet to confirm the existing rows of the Google sheet is updated:
def display_google_sheet_data():
try:
# Retrieves the Google Sheet data using Sheet Best API
response = requests.get(sheet_best_api_url) # Saves the API response as JSON into "data" variable_
if response.status_code == 200:
data = response.json()
print('=================Retrieve data from Google Sheet is Successful====================')
print(data)
else:
print('==================Retrieve data from Google Sheet is Successful===================')
except Exception as_ err:
print({'Error: ': err.args})Now we’ve completed the hard part of declaring all the functions. We shall program the order of sequence in calling each function:
# The workflow by calling the various functions
# 1) Pull Linkedin data from Proxycurl
# 2) Save and update the data into Google sheet with an existing row using Linkedin Data that was retrieved
# 3) Retrieve data from Google sheet and display the data using Sheet Best API.
live_data = get_linkedin_profile_data(profile_url)
save_linkedin_data(live_data, 0)
display_google_sheet_data()Alright, alright, alright, we can finally execute the python program. Which retrieves the data, save the data and display the updated Google sheet with the data in the console:
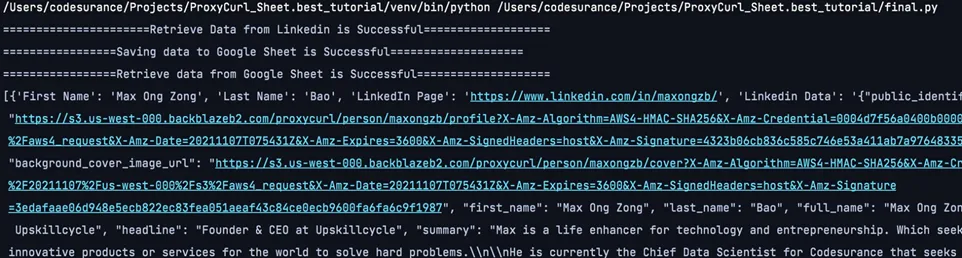
Success Execution of the “final.py”
Conclusions

Your journey has been complete young grasshopper. You now possess all the knowledge and concepts to use both Sheet Best and Proxycurl API.
- Retrieve data from Proxycurl API
- Displaying the data from Google Sheet using Sheet Best API
- Storing the LinkedIn data into existing rows using Sheet Best API

I would recommend that you do not spend alot of time and effort in building a data scrapper. Instead, rely on services like Sheet Best and Proxycurl to help you get started. Use the time and effort you had saved and redirect your focus on creating the lead generation system for your company.
Reference
- Sheet Best
- Proxycurl
- Lead Generation
- Prospects
- Visual Studio Code
- Requests
- What is an API?
- REST API Examples
- Evaluating the Top 5 LinkedIn Scraping Services
- Proxycurl LinkedIn Person Profile Endpoint
- [Get - Read Rows for Sheet Best](https://docs.Sheet Best/#get-read-rows)
- [PUT/PATCH - Update Rows for Sheet Best](https://docs.Sheet Best/#put-patch-update-rows)
- Data Scraping
- Unsplash