How to Scrape Website Data into Google Sheets (No Backend Required)

Ever wanted to scrape data from any website and store it online without spinning up servers or writing complex backend code? This guide shows you exactly how to do that by building a live NBA stats dashboard.
We’ll scrape the official NBA website, push the data straight into Google Sheets, and transform your spreadsheet into a powerful REST API—all with just a few lines of Python code. Whether you’re tracking sports stats, monitoring prices, or building any data collection project, this approach works for virtually any website.
What You’ll Build
- ⏱️ Setup time: 5 minutes from start to finish
- 📝 Code lines: Less than 50 lines of Python
- 💰 Cost: Free with trial accounts
- 🔄 Update frequency: Real-time or scheduled
- 📊 Data sources: Any website (30+ tested)
- 🚀 Scalability: Handle thousands of data points
Here’s what makes this approach powerful:
- Zero infrastructure: Google Sheets becomes your database
- Instant REST API: Sheet Best makes your spreadsheet accessible via a clean, simple API.
By the end, you’ll have scraped every NBA team’s stats and built a dashboard that updates with fresh data on demand.
You could scrape this data manually using libraries like BeautifulSoup or lxml, but that means wrestling with network errors, anti-bot protections, dynamic content, and fragile parsing logic.
Instead, we’ll use Scrapingdog to handle the hard scraping stuff and return clean, structured JSON data. Their AI-powered extraction means we can simply describe what we want instead of writing CSS selectors. Less debugging, more building!
Prerequisites: Python, API Keys, and Google Sheets Setup
We’ll use Python for this project since it excels at web scraping and API integration. The simple syntax and robust libraries make connecting to both Scrapingdog and Sheet Best straightforward.
Ready to build your first automated data pipeline? You’ll need accounts for both services. Both offer generous free trials, so you can complete this entire tutorial at no cost:
- Sheet Best at sheetbest.com - grab your API endpoint (starts free)
- Scrapingdog at scrapingdog.com - get your API key (1000 free requests)
Once you have both credentials, set them as environment variables:
export SCRAPINGDOG_KEY="your_scrapingdog_key_here"
export SHEETBEST_ENDPOINT="https://api.sheetbest.com/sheets/XXXXXXXX"All set. Let’s go! 🚀
Step 1: Set up Google Sheets API integration with Sheet Best
First, let’s set up our Google Sheet to store the NBA data:
- Create the spreadsheet: Open sheets.new in your browser
- Add column headers: In row 1, add these headers:
Team,Link,Profile,PPG,PPG Rank,RPG,RPG Rank,APG,APG Rank,OPPG,OPPG Rank - Connect to Sheet Best: Go to the Sheet Best dashboard, connect your sheet, and copy your REST endpoint (it looks like
https://api.sheetbest.com/sheets/abcd-1234)
Your sheet should look like this:
Test the connection to make sure everything’s working:
curl $SHEETBEST_ENDPOINT # should return []Step 2: Scrape NBA team data using Python and Scrapingdog API
Now we’ll scrape the NBA teams page to get all 30 teams and their links. The NBA website uses lots of JavaScript, but Scrapingdog handles that complexity for us.
Here’s the magic: instead of writing complex CSS selectors, we can just tell Scrapingdog what data we want using natural language:
# python example
response = requests.get("https://api.scrapingdog.com/scrape", params={
'api_key': SCRAPINGDOG_KEY,
'url': 'https://nba.com/teams',
'dynamic': 'false',
'ai_query': 'Give me the teams, with team name, team link and profile link'
})The ai_query parameter does all the heavy lifting—no CSS selectors, no DOM navigation, just plain English describing what we need.
Here’s the complete script that scrapes all teams and processes the URLs:
# scrape_teams.py
import os, requests
response = requests.get("https://api.scrapingdog.com/scrape", params={
'api_key': SCRAPINGDOG_KEY,
'url': 'https://nba.com/teams',
'dynamic': 'false',
'ai_query': 'Give me the teams, with team name, team link and profile link'
})
team_data = response.json()
# Process the links
teams = [
{
"Team": t["team_name"],
"Link": f"https://www.nba.com{t['team_link']}",
"Profile": f"https://www.nba.com{t['profile_link']}"
} for t in team_data
]
print(f"Found {len(teams)} teams")Step 3: Push the teams to Google Sheets with Sheet Best
With our team data ready, sending it to Google Sheets is surprisingly simple—just one API call:
resp = requests.post(SHEETBEST_ENDPOINT, json=teams)
print("Rows created:", len(resp.json()))That’s it! Sheet Best takes the entire array and creates individual rows automatically. Check your Google Sheet — you should see all 30 NBA teams populated instantly.
🎉 Congratulations! You’ve just built your first automated web scraping pipeline. Your Google Sheet is now a live database with a REST API. Want to take it further? Continue to Step 4 to add real-time statistics.
Step 4: Add real-time NBA stats with automated data enrichment
Here’s where it gets interesting. We’ll visit each team’s profile page to scrape their key performance stats — points per game (PPG), rebounds per game (RPG), assists per game (APG), and opponent points per game (OPPG) — along with their league rankings, with a lot of help from the ScrapingDog ai_query to get this transformed and formated in a single request.
# enrich_stats.py
import requests
rows = requests.get(SHEETBEST_ENDPOINT).json()
for row in rows:
raw_stats = requests.get("https://api.scrapingdog.com/scrape", params={
'api_key': SCRAPINGDOG_KEY,
'url': row['Profile'],
'dynamic': 'false',
'ai_query': 'Give me the team PPG and PPG Rank cardinal number, RPG and RPG Rank cardinal number, APG and APG Rank cardinal number , OPPG and and OPPG Rank cardinal number'
})
requests.patch(f"{SHEETBEST_ENDPOINT}/Team/{row['Team']}", json=raw_stats.json())⏱️ Add this to a cron job or GitHub Action to update it weekly.
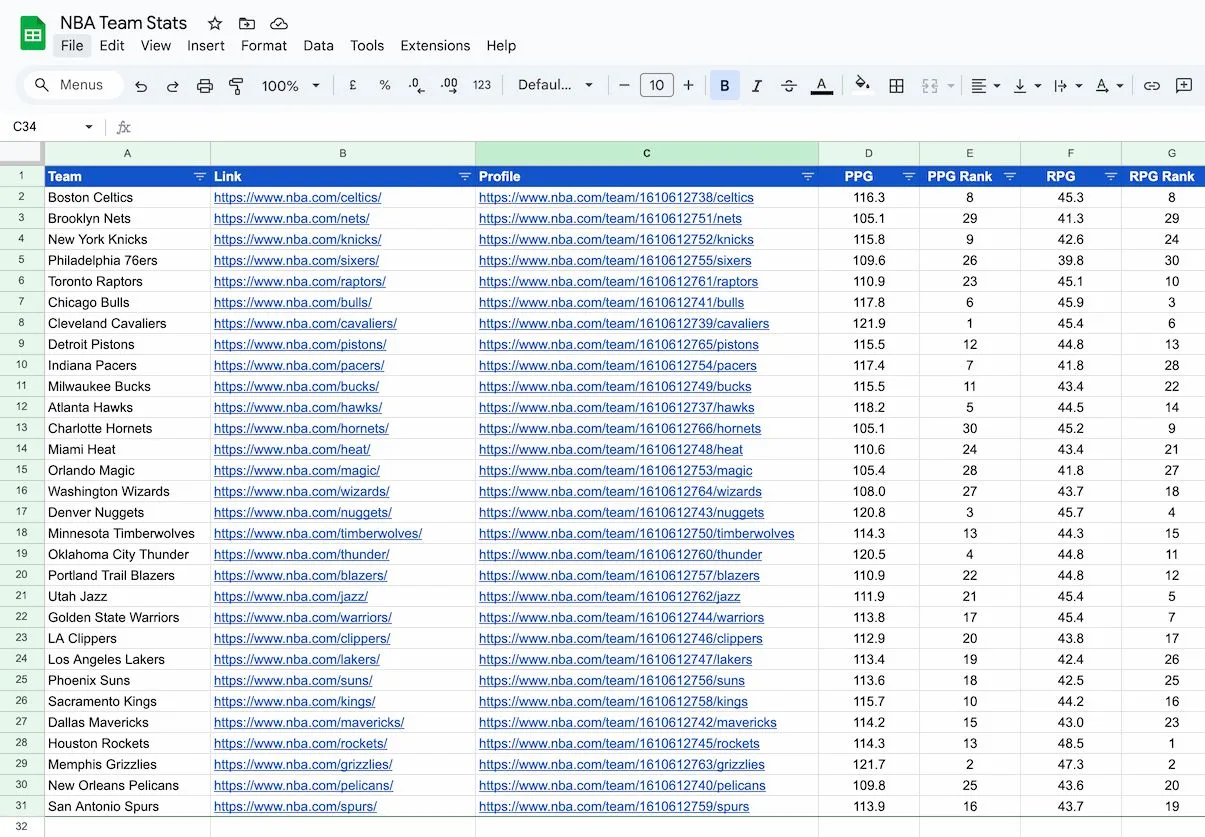
Here’s what the final sheet should look like:
Step 5: Want to go further?
Your sheet is now a real-time sports dashboard backend. You could:
- Make live visualizations in Google Sheets
- Build a site that reads from the REST API (e.g. React or Vue)
- Plug it into Looker Studio, Tableau, or Notion
Complete Python script for automated web scraping to Google Sheets
Combine everything into one file:
# stats_to_sheet.py
import os, requests
SCRAPINGDOG_KEY = os.getenv("SCRAPINGDOG_KEY")
SHEETBEST_ENDPOINT = os.getenv("SHEETBEST_ENDPOINT")
response = requests.get("https://api.scrapingdog.com/scrape", params={
'api_key': SCRAPINGDOG_KEY,
'url': 'https://nba.com/teams',
'dynamic': 'false',
'ai_query': 'Give me the teams, with team name, team link and profile link'
})
team_data = response.json()
# Process the links
teams = [
{
"Team": t["team_name"],
"Link": f"https://www.nba.com{t['team_link']}",
"Profile": f"https://www.nba.com{t['profile_link']}"
} for t in team_data
]
# Create the teams
resp = requests.post(SHEETBEST_ENDPOINT, json=teams)
print("Rows created:", len(resp.json()))
# Fetch team data from sheet best and update it
rows = requests.get(SHEETBEST_ENDPOINT).json()
for row in rows:
raw_stats = requests.get("https://api.scrapingdog.com/scrape", params={
'api_key': SCRAPINGDOG_KEY,
'url': row['Profile'],
'dynamic': 'false',
'ai_query': 'Give me the team PPG and PPG Rank cardinal number, RPG and RPG Rank cardinal number, APG and APG Rank cardinal number, OPPG and and OPPG Rank cardinal number'
})
requests.patch(f"{SHEETBEST_ENDPOINT}/Team/{row['Team']}", json=raw_stats.json())
print("All done! 🚀")Frequently Asked Questions
Can I scrape any website with this method?
Yes! Scrapingdog can handle most websites including those with JavaScript, anti-bot protection, and dynamic content. The AI-powered extraction works with complex layouts and can adapt to different site structures.
How often can I update the data?
You can run the script as often as needed. For production use, consider rate limits and implement delays between requests. Many users set up hourly or daily updates using cron jobs or GitHub Actions.
Is this method legal and ethical?
Always check the website’s robots.txt and terms of service before scraping. This method respects rate limits and doesn’t overload servers. For public data like sports stats, this approach is generally acceptable.
What if the website structure changes?
The AI-powered extraction is more resilient than traditional CSS selectors. If a site changes, you might just need to update your ai_query description rather than rewriting complex parsing logic.
Can I scale this for larger datasets?
Absolutely! Sheet Best can handle thousands of rows, and you can implement batching for very large datasets. Consider upgrading to paid plans for higher rate limits and more API calls.
What other data sources work with this method?
This pattern works for: e-commerce product catalogs, job listings, real estate prices, cryptocurrency rates, social media metrics, news articles, and virtually any publicly accessible data.
What you just accomplished
You’ve built something powerful with minimal code:
- Scraped complex, dynamic websites using AI-powered extraction
- Transformed Google Sheets into a full REST API backend
- Created a live sports dashboard that updates with fresh data
- Automated data collection without managing any infrastructure
This same pattern works for virtually any data source: e-commerce product catalogs, job listings, real estate prices, cryptocurrency rates, or social media metrics.
Take it further
Your NBA dashboard is just the beginning. Here are some ways to expand:
- Schedule automatic updates with GitHub Actions or cron jobs
- Build a frontend that reads from your Sheet Best API
- Monitor competitor pricing by scraping e-commerce sites
- Track job postings across multiple job boards
- Create alerts when data changes significantly
The combination of AI-powered scraping and spreadsheet APIs opens up endless possibilities for no-code data automation.
Ready to build your next data project? Get started with Sheet Best and start turning your spreadsheets into powerful APIs.